CFA
Konfirmatorische Faktoranalyse - Confiramtory Factor Analysis (CFA)
Im Gegensatz zu den explorativen Faktoranalyse-Formen wird hier eine bekannte Faktorenstruktur vorausgesetzt und ihr Fit auf einen Datensatz statistisch geprüft.
Modelltests
zwei Infos werden herangezogen
- Chi2 Test
- Fit-Indizes des Modells (CFI, RMSEA etc.)
Chi2 Test:
• Nullhypothese (H0) des Chi2 entspricht Modellkonformität (Das Modell passt zur Datenstruktur)
• Alternativhypothese (H1) führt zur Verwerfung des Modells (Das Modell weicht von der Datenstruktur ab)
• Test ist stichprobenabhängig Chi2 = (N-1) * F
• Chi2 < 2*df → H0, wenn Chi2 > 2*df →H1 (Daumenregel)
Fit-Indices
Diskrepanzfunktionen = “fitting functions” Prinzip: Minimierung des “Abstands” zwischen der beobachteten und der geschätzten Kovarianzmatrix
2 Arten von Fit-Indizes
Komparative Fit-Indizes: Vergleich mit “Null-Modell” (alle Variablen sind unkorreliert) (z. B. CFI)
Absolute Fit-Indizes: Vergleich mit “saturiertem Modell” (Modell mit perfektem Fit) (z. B. RMSEA, SRMR)
Einteilung
Goodness-of-Fit-Indizes: Wie gut beschreibt ein Modell die Daten? großer Wert ⇒ guter approximativer Modell-Fit
Badness-of-Fit-Indizes: Wie schlecht beschreibt ein Modell die Daten? kleiner Wert ⇒ guter approximativer Modell-Fit
Beispiel:
RMSEA: Root-Mean-Square-Error of Approximation Einteilung: Badness-of-Fit-Index (Wert nahe 0: guter Modell-Fit)
Geprüft wird, ob das Modell von den Daten abweicht und nicht, ob das Modell stimmt oder das beste ist! Es kann viele gleich gute Modelle geben.
CFA in Statistica
In Statistica existiert ein Assistent konfirmatorische Faktoranalyse:
"Statistik | höhere (nicht-) lineare Modelle | Strukturgleichungsmodelle" Reiter: "Pfadassistenten" Check "Konfirmatorische Faktoranalyse" dann "latente Variablen" (Faktoren) und "manifeste Variablen" (die Items, die dem jeweiligen Faktor zugeordnet sind) angeben. Das definiert das Modell.
Ergebnisse:
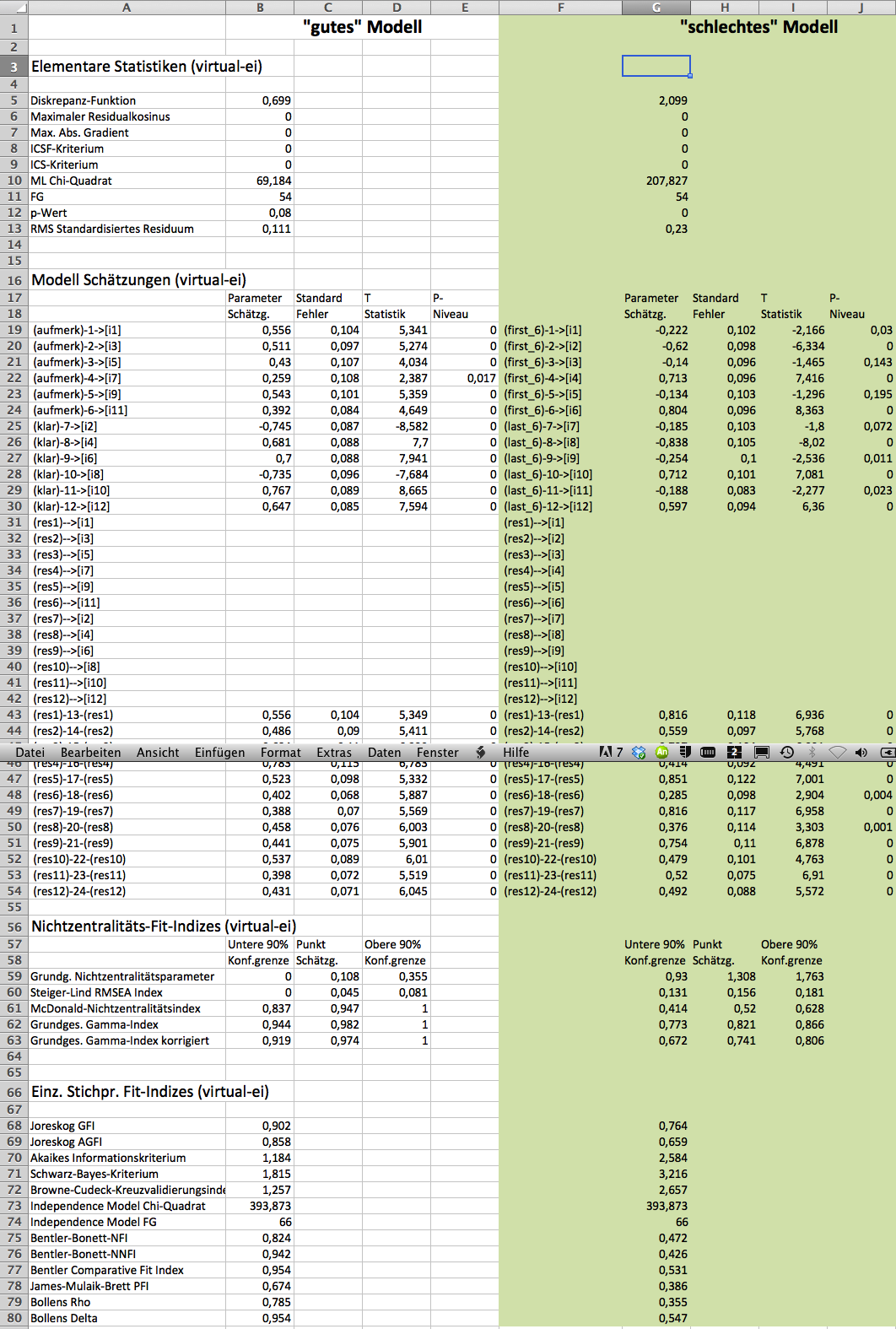
Elementare Statistiken: Diskrepanz-Funktion: Je höher der Wert, desto schlechter die Anpassung des Modells an die Daten. Chi^2 Wert mit df und p: Wenn sig. weichen die Daten sig. vom Modell ab.
Modell Schätzungen: hier finden sich die Pfad-Koeffizienten mit Signifikanztests
Nichtzentralitäts-Fit-Indizes: hier findet sich z. B. der oben angesprochene RMSEA
Einz. Stichpr. Fit-Indizes: hier findet sich u. a. das bekannte AIC (Akaikes Informationskriterium): je kleiner desto besser fittet das Modell die Daten.
Gegenüberstellung zweier Modelle im Output von Statistica
Beispiel Emotionale Intelligenz. Verglichen wir das passende Modell (gerade gegen ungerade Itemnummer) gegen ein unpassendes Modell (die ersten sechs gegen die letzten sechs Items)
[Abbildung in voller Auflösung]
{kind=link}
